Few-Shot Learning คืออะไร?

Few-Shot Learning คือหนึ่งในวิธีการเรียนรู้ของโมเดล Deep Learning (ML ก็ได้เช่นกัน) โดยมีวัตถุประสงค์หลักคือการแก้ปัญหาด้านชุดข้อมูลที่มีจำนวนจำกัด เพราะเป็นที่รู้กันดีว่าการจะเทรนโมเดล AI ให้เก่งได้นั้นจำเป็นจะต้องมีชุดข้อมูลที่มีคุณภาพและมี Label ระบุว่าข้อมูลนั้น ๆ คืออะไร แต่ในกรณีที่ข้อมูลนั้น ๆ เป็นข้อมูลที่หายากหรือมีต้นทุนสูงในการได้มาจะทำให้เราไม่สามารถหาข้อมูลได้มากพอเพื่อที่จะเทรนโมเดล ดังนั้น Few-Shot Learning จึงเป็นวิธีการที่จะใช้เพียงแค่ข้อมูลไม่กี่ข้อมูลต่อ Label เพื่อเทรนโมเดลและได้ผลลัพธ์ที่น่าพึงพอใจได้ (ในบทความนี้จะยกตัวอย่างเป็น Image Classification)
Few-shot Datasets เป็นอย่างไร?
เราสามารถแบ่งข้อมูลได้เป็นสองชุด ได้แก่ Base set และ Test Set โดยใน Test Set และภายใน Set จะแบ่งเป็น Support Set และ Query Set และโดยปกติแล้วหน้าตาของชุดข้อมูลก็จะเป็น ข้อมูล คู่กับ Label ของมัน

ดังตัวอย่างในรูปด้านบนนี้ มีทั้งหมด 5 Classes ได้แก่ Poutine (มันฝรั่งทอดราดซอส), Ice Cream, Garlic Bread, Gyoza, Lobster Roll Sandwich
และใน Support จะมี 5 รูปต่อคลาส ส่วนใน Query มี 10 รูปต่อคลาส (มองว่า Support Set คือชุดสำหรับเทรนโมเดล ส่วน Query Set คือสำหรับ Validation ก็ได้)
แต่ถ้ากล่าวกันในภาพรวมแล้วหากเราต้องการเทรนตั้งแต่เริ่มต้นนั้นจำเป็นจะต้องมีข้อมูล 2 ชุดใหญ่ ๆ คือ Meta Training (เรียกว่า Base Set) และ Meta Testing (Test Set) ซึ่งในทั้งสองเซตนี้ก็จะมี Support และ Query เป็นของตัวเอง แต่ความแตกต่างคือ Base Set นั้นจะเป็นชุดข้อมูลขนาดใหญ่มีข้อมูลจำนวนมากและหลากหลายคลาสเพื่อสอนให้โมเดลรู้จักที่จะเรียนรู้คอนเซปต์ของรูปภาพต่าง ๆ ก่อน ส่วนใน Test Set จะเป็นชุดที่ข้อมูลเป็นรูปภาพที่ค่อนข้างเฉพาะเจาะจงมากขึ้นตามงานที่เราต้องการให้โมเดลจำแนก (พูดง่าย ๆ คือ Base Set เราหาเป็น Public Dataset ขนาดใหญ่ ๆ มาก ๆ มาเทรนได้ ส่วน Test Set คือชุดที่เป็นข้อมูลของงานที่เราต้องการทำจริง ๆ ซึ่งชุดนี้หาได้ไม่มากและมีต้นทุนสูงในการได้มา)

ตัวอย่าง Base Set จะประกอบด้วยภาพจากหลาย ๆ คลาสและมีจำนวนเยอะมาก ๆ โดยแบ่งเป็น Episode ในแต่ละ Episode จะประกอบด้วย Support และ Query
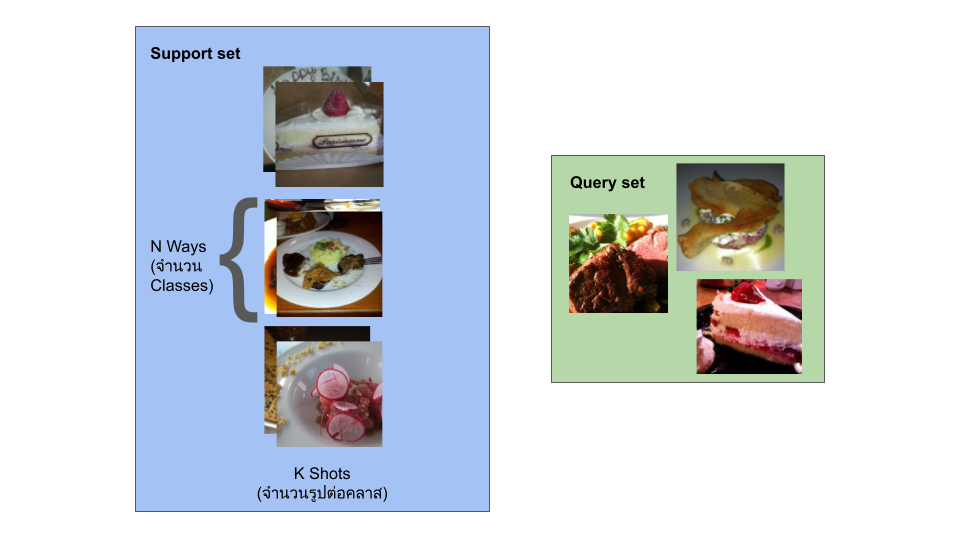
ส่วน Test Set จะเป็นชุดที่มีข้อมูลเฉพาะเจาะจงของงานที่เราสนใจ ดังในรูปนี้คือมีทั้งหมด 3 คลาสคือ Strawberry Shortcake, Steak, Tuna Tartare และ มี 2 รูปต่อคลาสเท่านั้น ส่วน Queryคือรูป Steak, Tuna Tartare, Strawberry Short Cake อื่น ๆ ที่โมเดลไม่เคยเห็นมาก่อน
Few-shot Models?
โดยปกติเราจะแยกเป็น 2 ส่วนคือ
- Feature Extraction Models ส่วนนี้จะทำหน้าที่แปลงข้อมูลให้อยู่ใน Feature Spaces (หรือก็คือส่วนที่ต้องเทรนด้วย Base Set) ในปัจจุบันเรามี Pretrained ขนาดใหญ่จำนวนมากแล้วทั้งด้าน NLP และ Computer Vision เพราะฉะนั้นหากงานเราไม่ได้เฉพาะเจาะจงมากจริง ๆ ก็ใช้ Pretrained เหล่านี้ได้เลย
- Meta Learning Network เป็นส่วนโมเดลที่จะเปรียบเทียบความคล้ายกันของฟีเจอร์ใน Feature Spaces (พูดง่าย ๆ คือถ้ามีรูปที่ไม่เคยเห็นมาก่อนส่งเข้ามาในโมเดล ตัวโมเดลควรจะพยายามที่จะบอกให้ได้ว่ารูปใหม่นี้คล้ายกับรูปประเภทไหนที่มันรู้จัก) โดยจะมี Algorithm ด้วยกัน 4 ประเภท (แต่ละแบบจะมีวิธีการเปรียบเทียบความคล้ายต่างกันออกไป)
- Model-Agnostic Meta-Learning (MAML)
- Matching Networks
- Prototypical Networks
- Relation Network
ตัวอย่างการ Implement Few-Shot Learning
ในที่นี้ใช้ชุดข้อมูลตัวอย่างของ PyTorch Food101 เป็นรูปอาหารพร้อมกับชื่ออาหารนั้น ๆ โดยเริ่มต้นเราจะต้องเตรียมข้อมูลให้อยู่ในฟอร์แมตที่เป็น Support Set กับ Query Set ก่อน ซึ่งแนะนำให้ใช้ไลบรารี่คือ
easyfsl ติดตั้งได้ดังนี้ pip install easyfsl
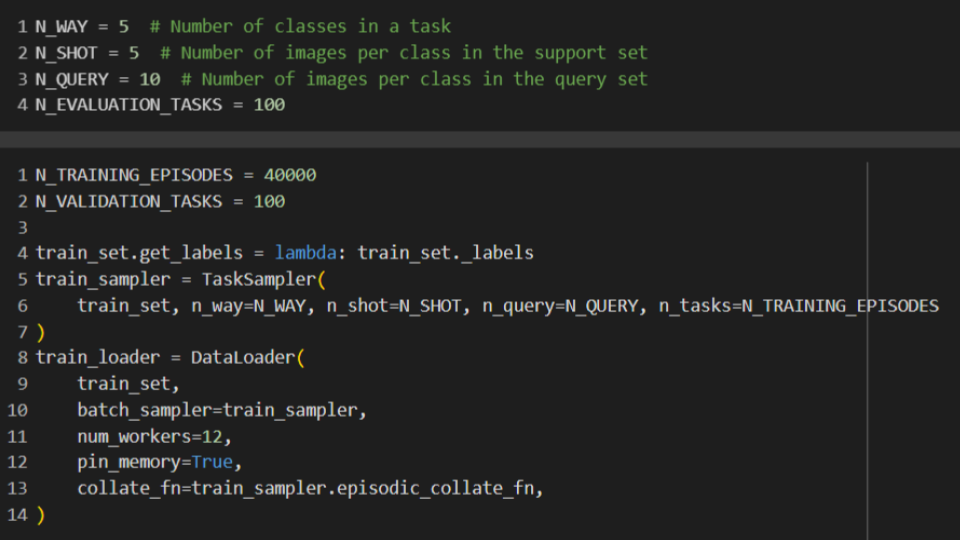
สร้าง Object ที่ Reference ถึงชุดข้อมูลนั้น จากนั้นกำหนด จำนวนคลาส จำนวนข้อมูล และจำนวน Query และ Episodes (สำหรับเทรน) และจำนวนชุด Evaluation (สำหรับเทส)
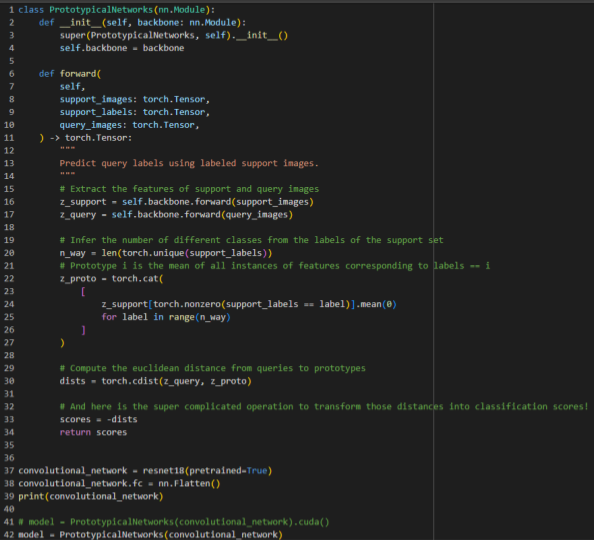
ตัวอย่างโมเดล Few-Shot Learning โดยใช้อัลกอริทึม Prototypical Networks เป็น Meta Learning และ Feature Extraction เป็น RestNet18 (เป็นของ PyTorch ซึ่งเทรนมาแล้วเรียบร้อย) ฉะนั้นในรูปนี้ก็คือเรากำลังจะเทรนส่วน Meta Learning นั่นเอง
ในส่วนของการเทรนสามารถทำได้ตามถนัด โดยวิธีการตาม Framework ของ PyTorch (ซึ่งทำได้หลายแบบมาก ๆ เรียกว่าตามถนัดเลย หรือจะย้อนไปดูบทความก่อน ๆ ก็ได้) ทั้งนี้หากต้องการตัวอย่างที่ง่ายเพื่อเริ่มต้น ขอแนะนำให้ดู โค้ดที่นี่ และ บทความที่นี่
ขอแนะนำให้ทำความเข้าใจชุดข้อมูลกับวิธีการเตรียมให้พร้อมใช้งานก่อน จากนั้นจึงค่อยลงมือเทรนโมเดล