What is Model Optimization?

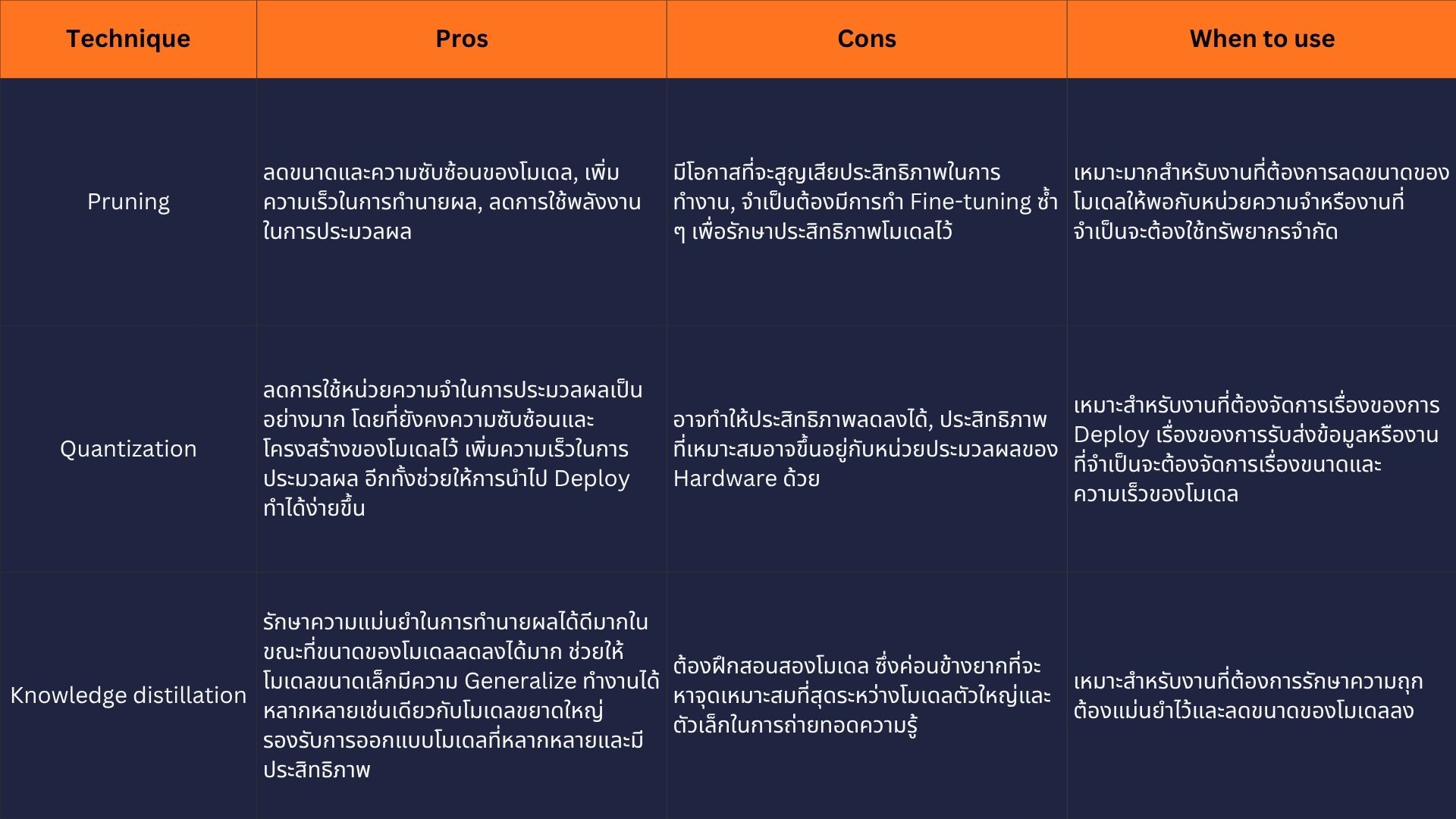
การปรับปรุงประสิทธิภาพโมเดลหรือ Model Optimization มีวัตถุประสงค์หลักคือการลดทรัพยากรที่ต้องใช้ในการประมวลผลให้น้อยลง (Reduce Computational Costs) ลดขนาดของโมเดลและหน่วยความจำที่ต้องใช้ (Reduce Memory Usage) โดยที่ยังคงรักษาประสิทธิภาพการทำงานเอาไว้ให้ดีเหมือนเดิมด้วยหรือในบางกรณีเองก็ส่งผลให้โมเดลทำงานได้ดีขึ้นด้วย
Deep Learning โมเดลคือเครือข่ายประสาทเทียมหลายชั้นที่เชื่อมต่อกันเป็นจำนวนมากโดยที่แต่ละชั้นจะมี Neurons อยู่นับพัน ๆ ตัว และการเชื่อมต่อกันของ Neurons แต่ละตัวจะมีการกำหนดไว้ว่าจะส่งผลต่อกันมากน้อยแค่ไหนด้วย Weights ซึ่งสถาปัตยกรรมของโมเดลมีพื้นฐานจากการใช้หลักการคำนวณทางคณิตศาสตร์อย่างง่ายมาเชื่อมต่อกันและเลือกที่จะส่งผลระหว่างกันอย่างไรจนได้ผลลัพธ์ที่ต้องการ และวิธีนี้ได้พิสูจน์ให้เห็นว่ามันมีประสิทธิภาพในการทำงานหลายอย่างเช่น การรู้จำรูปแบบต่าง ๆ (ภาพ, เสียง, ข้อความ, ข้อมูลใด ๆ ที่มีรูปแบบ), การตัดสินใจเลือกสิ่งต่าง ๆ เป็นต้น
แต่ในขณะเดียวกันการที่โมเดลมีความสามารถในการคำนวณที่ประสิทธิภาพขนาดนี้มันก็แลกมากับการที่ต้องมีเครื่องมือประมวลผลเฉพาะทางอย่าง GPUs และ TPUs ซึ่ง Deep Learning โมเดลต้องใช้ทรัพยากรในการประมวลผลที่สูงมากและต้องการข้อมูลอย่างมหาศาลในการเรียนรู้ให้ได้ประสิทธิภาพ นอกจากนี้ยังต้องใช้เวลาที่นานในการสร้างโมเดลขนาดใหญ่ขึ้นมารวมถึงส่งผลกระทบต่อสิ่งแวดล้อมอย่างมีนัยยะสำคัญ จึงเป็นเหตุผลว่าทำไมเราถึงมีการปรับปรุงประสิทธิภาพโมเดลนั่นเอง
Pruning
เทคนิคลดความซับซ้อนของโมเดลด้วยการลดส่วนที่ทำซ้ำกัน
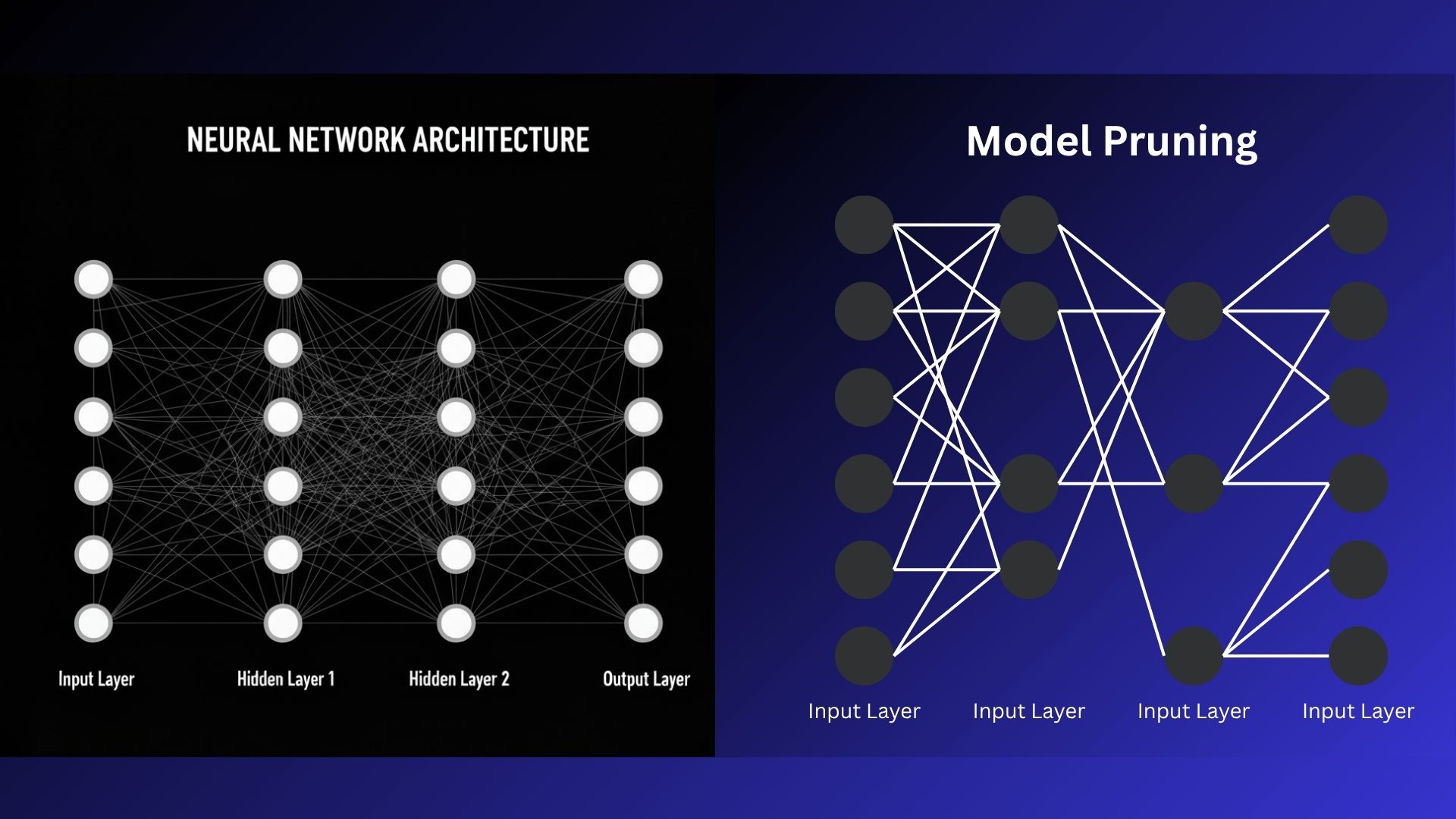
Pruning คือ Model Optimization เทคนิคที่จะเลือกและลดทั้งการเชื่อมต่อระหว่างนิวรอนและลบตัวนิวรอนที่ทำหน้าที่ซ้ำ ๆ กันออกไปโครงข่ายของโมเดลโดยที่ไม่กระทบอะไรกับประสิทธิภาพการทำงานมากเกินไป เทคนิคนี้มีพื้นฐานมาจากการสังเกตว่าแต่ละเซลล์นิวรอนไม่ให้ทำงานเท่ากันทั้งหมดในการคิดให้คำตอบของโมเดล ดังนั้นการระบุนิวรอนที่มีความสำคัญน้อย ๆ และลบออกไปนั้นจะช่วยลดขนาดและความซับซ้อนของโมเดลได้เป็นอย่างมากโดยที่ไม่กระทบต่อการทำงานของโมเดลในเชิงลบ
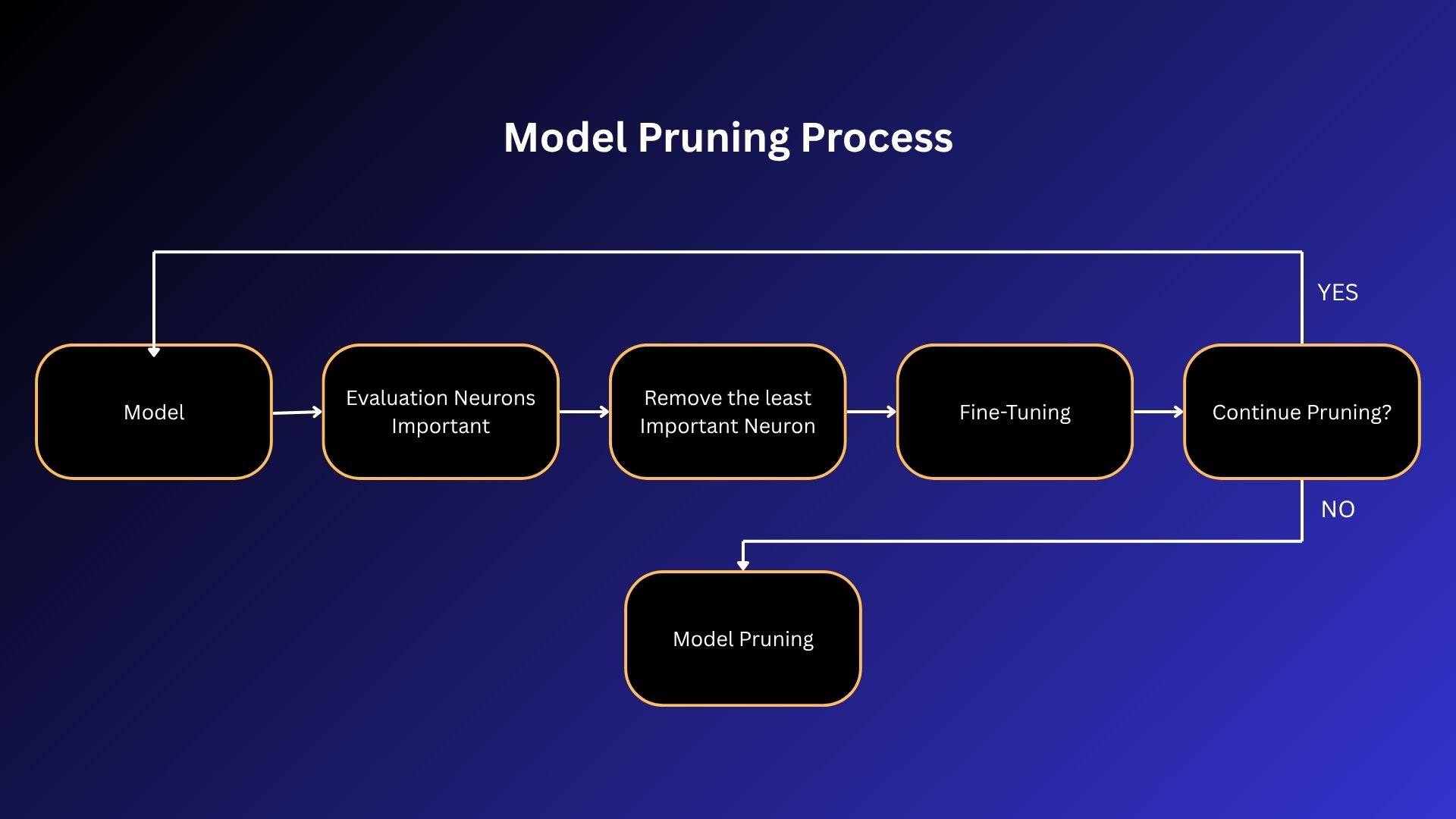
การ Pruning มีขั้นตอนด้วยกัน 3 อย่างคือ Identification, Elimination, และ Fine-tuning
- Identification: ขั้นตอนนี้คือการสำรวจและระบุว่า Weights และนิวรอนส่วนไหนบ้างที่จะลดได้ วิธีการเช่น Sensitivity Analysis ตรวจสอบว่าการเปลี่ยนแปลง Weights ส่งผลต่อผลลัพธ์ของโมเดลอย่างไรบ้าง หรือการใช้ตัวชี้วัดอย่าง Magnitude Measure มาวัดความสำคัญของนิวรอนและ Weights แต่ละตัวก็ได้
- Elimination: เลือกลบ Weights และนิวรอนที่ไม่จำเป็นออกจากแบบจำลอง
- Fine-tuning: ขั้นตอนนี้เป็นการฝึกสอนโมเดลใหม่อีกครั้งหลังจากลด Weights และนิวรอนออกไปแล้วเพื่อให้โมเดลที่มีขนาดเล็กลงนี้ยังคงประสิทธิภาพการทำงานเดิมไว้หรืออาจเพิ่มมากขึ้น แต่ทั้งนี้หากใน 2 ขั้นตอนแรกให้ผลลัพธ์ที่ดีมากพอแล้วก็ไม่จำเป็นต้องทำขั้นตอนนี้ก็ได้
ในการทำ Model Pruning นั้น มีวิธีการหลัก ๆ ในการเลือกตัดแต่งองค์ประกอบของโมเดล 2 วิธีการ ดังนี้:
- Structured Pruning (การตัดแต่งแบบมีโครงสร้าง) นี่คือการนำกลุ่มค่าน้ำหนักทั้งหมดออกไป (เช่น แชนแนล หรือ เลเยอร์) ซึ่งจะส่งผลให้ได้สถาปัตยกรรมที่กระชับยิ่งขึ้น (leaner architecture) ข้อดีคือช่วยให้ฮาร์ดแวร์ทั่วไปอย่าง CPUs และ GPUs สามารถประมวลผลได้อย่างมีประสิทธิภาพมากขึ้น แต่ในขณะเดียวกัน การนำองค์ประกอบย่อยทั้งหมดออกจากสถาปัตยกรรมของโมเดล ก็อาจส่งผลให้ประสิทธิภาพในการทำงาน (task performance) ลดลงอย่างมีนัยสำคัญ เนื่องจากอาจทำให้รูปแบบที่ซับซ้อนซึ่งเครือข่ายได้เรียนรู้ไว้ (complex, learned patterns) สูญหายไป
- Unstructured Pruning (การตัดแต่งแบบไม่มีโครงสร้าง) นี่คือการมุ่งจัดการกับค่าน้ำหนักรายตัว (individual weights) ที่มีความสำคัญน้อยทั่วทั้งเครือข่ายประสาทเทียม ซึ่งจะนำไปสู่รูปแบบการเชื่อมต่อที่เบาบาง (sparse connectivity pattern) แม้ว่าความเบาบางนี้จะช่วยลดขนาดการใช้หน่วยความจำ (memory footprint) ได้ แต่ก็มักจะไม่ส่งผลให้การประมวลผลเร็วขึ้นบนฮาร์ดแวร์มาตรฐานอย่าง CPUs และ GPUs ซึ่งเป็นอุปกรณ์ที่ถูกปรับแต่งมาเพื่อรองรับเครือข่ายที่มีการเชื่อมต่อแบบหนาแน่น (densely connected networks) อยู่แล้ว
Quantization การลดขนาดหน่วยความจำด้วยการลดความแม่นยำในการประมวลผล

Quantization คือเทคนิคที่มีเป้าหมายเพื่อลดความต้องการใช้หน่วยความจำ (memory needs) และปรับปรุงประสิทธิภาพการประมวลผล (computing efficiency) โดยการแทนค่าค่าน้ำหนัก (weights) ด้วยความแม่นยำที่น้อยลง (less precision) โดยทั่วไป ค่าน้ำหนัก (weights) จะถูกแทนค่าด้วยตัวเลขทศนิยมแบบ 32 บิต (32-bit floating-point numbers) ซึ่งเป็นรูปแบบที่เรียกว่า single-precision floating-point format การลดขนาดนี้ลงเหลือ 16, 8 หรือแม้แต่น้อยกว่านั้น และการใช้ตัวเลขจำนวนเต็ม (integers) แทนที่ตัวเลขทศนิยม (floating-point numbers) สามารถลดขนาดการใช้หน่วยความจำ (memory footprint) ของโมเดลได้อย่างมีนัยสำคัญ การประมวลผลและการย้ายข้อมูลที่น้อยลงยังช่วยลดความต้องการแบนด์วิดท์หน่วยความจำ (memory bandwidth) ซึ่งเป็นปัจจัยสำคัญอย่างยิ่ง (a critical factor) ในสภาพแวดล้อมการประมวลผลหลายรูปแบบ นอกจากนี้ การคำนวณที่แปรผันตามจำนวนบิต (computations that scale with the number of bits) ก็จะทำได้เร็วขึ้น ส่งผลให้ความเร็วในการประมวลผล (processing speed) ดีขึ้นด้วย
เทคนิค Quantization สามารถแบ่งกว้าง ๆ ได้เป็น 2 ประเภทดังนี้:
Post-training quantization (PTQ) เป็นแนวทางที่นำไปใช้ หลังจาก ที่โมเดลได้รับการฝึกฝนอย่างเต็มที่แล้ว โดยค่าน้ำหนัก (weights) ที่มีความแม่นยำสูง (high-precision) จะถูกแปลงไปเป็นรูปแบบที่มีบิตต่ำกว่า (lower-bit formats) โดยไม่จำเป็นต้องทำการฝึกสอนใหม่ (retraining)
วิธีการแบบ PTQ นั้นน่าสนใจสำหรับการนำโมเดลไป Deploy อย่างรวดเร็ว โดยเฉพาะบนอุปกรณ์ที่มีทรัพยากรจำกัดอย่างไรก็ตาม Accuracy อาจลดลง และการลดรูปไปเป็นการแทนค่าด้วยบิตที่ต่ำกว่าอาจทำให้เกิดการสะสมของข้อผิดพลาดจากการประมาณค่า (approximation errors) ซึ่งจะส่งผลกระทบอย่างเห็นได้ชัดในงานที่ซับซ้อนเช่น Detailed Image Recognition หรืองานด้าน NLP เป็นต้น
องค์ประกอบที่สำคัญอย่างยิ่ง (a critical component) ของ PTQ คือการใช้ Calibration Data (ข้อมูลสำหรับสอบเทียบ) ซึ่งมีบทบาทสำคัญในการ Optimization รูปแบบของ Quantization ให้เหมาะสมกับโมเดล โดยพื้นฐานแล้ว Calibration Data คือชุดข้อมูลตัวแทน (representative subset) ที่ดึงมาจากชุดข้อมูลทั้งหมดที่โมเดลจะต้องใช้ในการอนุมาน
มันทำหน้าที่ 2 ประการหลัก:
- การกำหนดพารามิเตอร์ของ Quantization (Determination of quantization parameters): Calibration data ช่วยในการกำหนดพารามิเตอร์ที่เหมาะสมสำหรับ weights และ activations ของโมเดล โดยการประมวลผลชุดข้อมูลตัวแทนนี้ผ่านโมเดลที่ถูกทำ Quantized แล้ว จะทำให้สามารถสังเกตการกระจายตัวของค่า (distribution of values) และเลือก scale factors (ตัวคูณปรับขนาด) และ zero points (จุดศูนย์) ที่ช่วยลดข้อผิดพลาดจาก Quantization (quantization error) ให้เหลือน้อยที่สุด
- การลดผลกระทบจากข้อผิดพลาดในการประมาณค่า (Mitigation of approximation errors): PTQ เกี่ยวข้องกับการลดความแม่นยำ (precision) ของ weights ซึ่งย่อมนำไปสู่ข้อผิดพลาดในการประมาณค่าอย่างหลีกเลี่ยงไม่ได้ Calibration data จะช่วยให้สามารถประเมินผลกระทบของข้อผิดพลาดเหล่านี้ต่อผลลัพธ์ของโมเดลได้ โดยการประเมินประสิทธิภาพของโมเดลบน calibration dataset นี้ เราจะสามารถปรับพารามิเตอร์ของ Quantization เพื่อบรรเทาข้อผิดพลาดเหล่านี้ ซึ่งจะช่วยรักษาความแม่นยำของโมเดลไว้ให้ได้มากที่สุด
Quantization-aware training (QAT) แนวทางนี้จะผสานกระบวนการ Quantization เข้าไป ในระหว่าง ขั้นตอนการฝึกสอนโมเดล (training phase) เลย ซึ่งเป็นการปรับสภาพ (acclimatizing) ให้โมเดลคุ้นชินกับการทำงานภายใต้ข้อจำกัดด้านความแม่นยำที่ต่ำกว่า (lower precision constraints) การกำหนดข้อจำกัดของ Quantization ในระหว่างการฝึกสอนนี้ จะช่วยลดผลกระทบจากการแทนค่าด้วยบิตที่ลดลง (reduced bit representation) โดยเปิดโอกาสให้โมเดลได้เรียนรู้ที่จะชดเชย (compensate) ข้อผิดพลาดในการประมาณค่าที่อาจเกิดขึ้น นอกจากนี้ QAT ยังช่วยให้สามารถทำการ Fine-tuning กระบวนการ Quantization สำหรับเลเยอร์หรือองค์ประกอบที่เฉพาะเจาะจงได้อีกด้วย
ผลลัพธ์ที่ได้คือโมเดล Quantized ที่โดยธรรมชาติแล้วมีความทนทาน (robust) มากกว่า และเหมาะสมกว่าสำหรับการนำไปใช้งานบนอุปกรณ์ที่มีทรัพยากรจำกัด โดยไม่ต้องแลกมากับการสูญเสียความแม่นยำอย่างมีนัยสำคัญอย่างที่มักจะพบในวิธีการแบบ PTQ
Distillation
เทคนิคการบีบอัดโมเดลด้วยการถ่ายโอนความรู้

Knowledge distillation คือเทคนิคการปรับปรุงประสิทธิภาพ (optimization technique) ที่ถูกออกแบบมาเพื่อถ่ายทอดความรู้ (transfer knowledge) จากโมเดลที่มีขนาดใหญ่และซับซ้อนกว่า (เรียกว่า “teacher” หรือ “ครู”) ไปยังโมเดลที่เล็กกว่าและมีประสิทธิภาพในการประมวลผลมากกว่า (เรียกว่า “student” หรือ “นักเรียน”)
แนวทางนี้มีพื้นฐานมาจากแนวคิดที่ว่า แม้ว่าอาจจำเป็นต้องใช้โมเดลขนาดใหญ่ที่ซับซ้อนในการเรียนรู้รูปแบบ (patterns) ในข้อมูล แต่โมเดลที่เล็กกว่าก็สามารถเข้ารหัส (encode) ความสัมพันธ์เดียวกันนั้น และไปถึงจุดที่มีประสิทธิภาพในการทำงาน (task performance) ใกล้เคียงกันได้ เทคนิคนี้เป็นที่นิยมใช้มากที่สุดกับโมเดลประเภทการจำแนกประเภท (classification) (ทั้งแบบ binary หรือ multi-class) ที่มีฟังก์ชัน softmax activation ในเลเยอร์ผลลัพธ์ (output layer) ในเนื้อหาต่อไปนี้ เราจะมุ่งเน้นไปที่การประยุกต์ใช้ในลักษณะนี้ แม้ว่าที่จริงแล้ว knowledge distillation จะสามารถนำไปประยุกต์ใช้กับโมเดลและงาน (tasks) อื่น ๆ ที่เกี่ยวข้องได้เช่นกัน
สถาปัตยกรรมแบบครู-นักเรียน (Teacher-student architecture): โมเดลครู (teacher model) คือเครือข่ายที่มีศักยภาพสูง (high-capacity network) ซึ่งมีประสิทธิภาพที่แข็งแกร่งในการทำงานตามโจทย์เป้าหมาย (target task) ส่วนโมเดลนักเรียน (student model) จะมีขนาดเล็กกว่าและมีประสิทธิภาพในการประมวลผล (computationally more efficient) มากกว่า
Distillation loss (การสูญเสียจากการกลั่นความรู้): โมเดลนักเรียนจะถูกฝึกฝนไม่เพียงแค่ให้ลอกเลียน (replicate) ผลลัพธ์ของโมเดลครูเท่านั้น แต่ต้องจับคู่ (match) การกระจายตัวของผลลัพธ์ (output distributions) ที่โมเดลครูสร้างขึ้นด้วย (โดยทั่วไป knowledge distillation จะใช้กับโมเดลที่มี softmax output activation) สิ่งนี้ช่วยให้โมเดลนักเรียนสามารถเรียนรู้ความสัมพันธ์ระหว่างกลุ่มตัวอย่างข้อมูล (data samples) และป้ายกำกับ (labels) ที่โมเดลครูได้เรียนรู้ไว้ กล่าวคือ—ในกรณีของงานจำแนกประเภท (classification tasks)—มันคือการเรียนรู้ตำแหน่งและทิศทางของขอบเขตการตัดสินใจ (decision boundaries) นั่นเอง
ในการนำวิธี Knowledge Distillation มาใช้งานนั้นจะมีด้วยกันหลายวิธีแต่ละวิธีส่งผลต่อประสิทธิภาพและผลการทำงานของโมเดลที่รับองค์ความรู้มา โดยแนวคิดแล้วเราต้องการสอนโมเดลตัวเล็กให้รู้ว่าโมเดลตัวตั้งต้นมีวิธีคิดอย่างไรซึ่งรวมถึงความไม่แน่นอนของผลลัพธ์ด้วย ยกตัวอย่างเช่นในงาน Binary Classification โมเดลตัวใหญ่ให้ผลลัพธ์โดยที่มีความน่าจะเป็นคือ [0.53, 0.47] นั้น เราก็ต้องการโมเดลตัวเล็กตอบถูกในคลาสเดียวกันโดยที่ยังมีความน่าจะเป็นที่เท่ากันหรือใกล้เคียงกันกับ [0.53, 0.47] ด้วย และส่วนต่างที่เกิดขึ้นระหว่างโมเดลตัวใหญ่และโมเดลตัวเล็กนั้นเราเรียกว่า Distillation Loss ซึ่งจะประกอบด้วย Cross-Entropy ที่วัดความถูกต้องและ Distillation Loss ที่วัดความคล้ายกับโมเดลต้นฉบับ
Model Architecture Compatibility โมเดลตัวใหญ่กับโมเดลตัวเล็กจำเป็นจะต้องมีโครงสร้างที่เข้ากันได้กล่าวคือโมเดลตัวเล็กจะต้องถูกออกแบบมาให้แก้ปัญหาเดียวกันได้โดยที่ลดความซับซ้อนของโมเดลตัวใหญ่ลงด้วย ดังนั้นจึงจำเป็นต้องทดลองเพิ่มลดแก้ไขเลเยอร์ต่าง ๆ เพื่อให้เรียนรู้ Insight จากโมเดลตัวใหญ่ได้ใกล้เคียงที่สุด
Transferring intermediate representations หรือ feature-based knowledge distillation เป็นอีกวิธีการถ่ายทอดองค์ความรู้ให้โมเดลตัวเล็กที่นอกเหนือจากการทำให้ผลลัพธ์ใกล้เคียงกัน การทำให้ฟีเจอร์ที่โมเดลตัวเล็กต้องเรียนรู้หรือใช้งานเหมือนกับโมเดลตัวใหญ่หรือการทำ Attention Maps เองก็ช่วยให้โมเดลตัวเล็กสามารถเรียนรู้และให้ผลลัพธ์ได้ใกล้เคียงมากขึ้นเช่นกัน
Conclusion