







AI-OMS ระบบ AI Agent Business ที่จะช่วยให้ธุรกิจ SME ดำเนินงานง่ายขึ้น ลดต้นทุน เพิ่มประสิทธิภาพการทำงาน วางโครงสร้างพื้นฐานให้พร้อมกับยุค AI
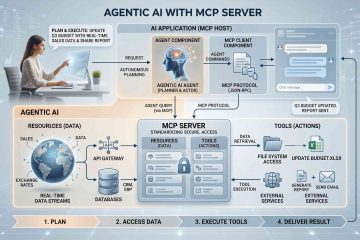
การสร้าง AI Agent ในปัจจุบันหากเราต้องการเตรียมความพร้อมสำหรับการมี Agent หลายตัวหรือการเพิ่มลดจัดการเครื่องมือนั้นเราจำเป็นต้องใช้ MCP
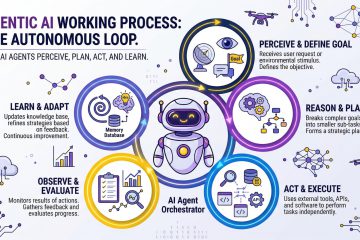
วิธีสร้าง AI Agents สำหรับใช้งานบนเครื่องคอมพิวเตอร์ตัวเองแบบไม่ต้องเสียเงินค่า LLM ใช้ทำงานได้หลากหลายตามการออกแบบ