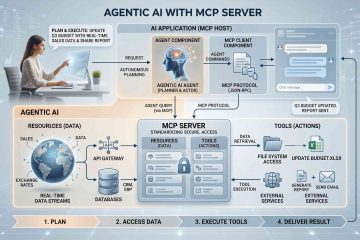
วิธีใช้งาน LangGraph

LangGraph คือ Framework ที่ถูกพัฒนาโดยทีมงาน LangChain เพื่อใช้สำหรับสร้าง Agentic AI หรือระบบ AI ที่มีความซับซ้อนสูง โดยเน้นการควบคุมการทำงานที่มีลักษณะเป็น Graph, มีโครงสร้างลูปทำงานซ้ำๆ (Cyclic Actions) และสามารถจัดการสถานะความทรงจำระหว่างทำงาน (State Management) ได้อย่างครบวงจร ข้อแตกต่างกับ LangChain หากกล่าวโดยสรุปจะมีข้อแตกต่างดังนี้
LangChain แบบดั้งเดิม: เปรียบเสมือนการต่อท่อสายพานลำเลียง (Chain) จากจุด A ไป B ไป C วิ่งเป็นเส้นตรง (DAG – Directed Acyclic Graph) ไม่สามารถหันหลังกลับหรือวนลูปได้ง่าย ๆ หากสายพานหลุดหรือ LLM คิดสับสน ระบบจะพังทันที
LangGraph: เปรียบเสมือนการสร้าง “โครงข่ายรางรถไฟ (Graph)” ที่มีสถานีจอดพัก (Nodes) มีป้ายทางแยกคอยสับรางตัดสินใจ (Edges) และรถไฟสามารถวิ่งวนกลับมาสถานีเดิมเพื่อคิดใหม่ทำใหม่ (Loops) ได้จนกว่างานจะสำเร็จ
3 หลักการสำคัญของ LangGraph ที่ทำให้ระบบมีความได้เปรียบสำหรับงาน Agentic AI มีดังต่อไปนี้
- โครงสร้างแบบกราฟที่ประกอบด้วย Nodes กับ Edges
- Node เปรียบเสมือนฟังก์ชันหรือจุดที่ระบบจะทำงาน กล่าวคือเป็นฟังก์ชัน Python หรือคำสั่งที่เราเขียนขึ้นมา เช่น Node ให้ LLM คิด, Node ให้ Tool ดึงข้อมูล, Node ทำความสะอาดข้อมูล
- Edges คือตัวเชื่อมต่อระหว่าง Node ใช้สำหรับตัดสินใจว่าจะทำงานอย่างไร โดยใน LangGraph เราสามารถกำหนดเงื่อนไขได้ด้วย Conditional Edges เช่น ให้ LLM ตรวจสอบคำตอบก่อน ถ้าคำตอบยังไม่ดีพอ ให้วิ่งกลับไปทำงานใหม่ที่ Node เดิมก่อน
- การควบคุมการทำงานได้อย่างสมบูรณ์ด้วย Cycle / Loops โดย LangGraph ออกแบบมารองรับการทำงานแบบ Cycle ได้ดีมาก มาพร้อมกับ Recursion Limit ช่วยป้องกันการทำงานซ้ำแบบไม่สิ้นสุด
- หน่วยความจำสถานะและความจำถาวร (State Management & Persistence)
- LangGraph ใช้แนวคิดที่เรียกว่า State-Driven ข้อมูลทุกอย่างที่เกิดขึ้นระหว่างที่บอตทำงานจะถูกบันทึกไว้ในสมุดจดส่วนกลาง (State) ทำให้ทุก ๆ Node สามารถอ่านและอัปเดตข้อมูลก้อนเดียวกันได้ตลอดเวลา
- Checkpointer ในตัวสแนปชอตเก็บความทรงจำไว้ได้ สามารถทำระบบ Memory คุยแยกรายคน (Thread Memory) หรือทำระบบ “Time Travel” เพื่อย้อนเวลากลับไปแก้ไขคำสั่งในอดีตของ Agent ได้
LangGraph Implementation
ในตัวอย่างนี้จะแสดงตัวอย่างเบื้องต้นสำหรับ วิธีใช้งาน LangGraph สร้าง Agentic AI ตรวจสอบราคาคริปโตและราคาหุ้นพร้อมส่งข้อความกลับมาในรูปแบบตารางบน LINE OA กัน เริ่มต้นกันที่เตรียม Project ก่อน โครงสร้างโปรเจคจะมีหน้าตาดังนี้
langgraph-line-agent/
├── .env # เก็บ API Keys และ LINE Secrets
├── config.py # ใช้ Pydantic Settings โหลด Config
├── tools.py # เครื่องมือให้ Agent เรียกใช้ (Free API / Mock)
├── agent.py # โครงสร้าง LangGraph (State, Nodes, Edges)
├── app.py # LINE Webhook Server (FastAPI)
└── pyproject.toml # จัดการด้วย uv
จากนั้นติดตั้ง Library ต่าง ๆ ที่จำเป็นดังต่อไปนี้
uv add langgraph langchain-openai langchain-core pydantic-settings fastapi uvicorn line-bot-sdk
httpx
ใน .env ไฟล์ให้ใส่ API Keys ต่าง ๆ ที่จำเป็นไว้ในที่นี้จะมีคีย์ของ LLM เจ้าต่าง ๆ ได้แก่ Typhoon, Thai LLM และของ Google AI ส่วนการเชื่อมต่อ LINE ดูได้ที่นี่
GOOGLE_API_KEY='YOUR_API_KEY'
TYPHOON_API_KEY='YOUR_API_KEY'
THAI_LLM_API_KEY='YOUR_API_KEY'
LINE_CHANNEL_ACCESS_TOKEN='YOUR_API_KEY'
LINE_CHANNEL_SECRET='YOUR_API_KEY'
สร้าง Configuration Layer (config.py) ใช้ Pydantic Settings อ่านค่าจาก .env เพื่อนำไปใช้งานต่อในไฟล์อื่นๆ อย่างปลอดภัยและมีการตรวจสอบค่าก่อน
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
# Pydantic maps these automatically from DATABASE_URL, GOOGLE_API_KEY, etc.
database_url: str
google_api_key: str
typhoon_api_key: str
thai_llm_api_key: str
line_channel_access_token: str
line_channel_secret: str
# Tell Pydantic to prioritize loading from the .env file
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
extra="ignore" # Ignores extra environment variables not defined here
)
สร้าง Configuration Layer (config.py) ใช้ Pydantic Settings อ่านค่าจาก .env เพื่อนำไปใช้งานต่อในไฟล์อื่นๆ อย่างปลอดภัยและมีการตรวจสอบค่าก่อน
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
# Pydantic maps these automatically from DATABASE_URL, GOOGLE_API_KEY, etc.
database_url: str
google_api_key: str
typhoon_api_key: str
thai_llm_api_key: str
line_channel_access_token: str
line_channel_secret: str
# Tell Pydantic to prioritize loading from the .env file
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
extra="ignore" # Ignores extra environment variables not defined here
)
สร้าง Tools สำหรับ Agent (tools.py) โดยจะให้ Agent เรียกใช้ API ภายนอกได้ ในตัวอย่างนี้เราจะใช้ Free Crypto Price API กับ Yahoo Finance รวมถึงการสร้าง Flex Message ด้วย และเทคนิคยอดนิยมของ LangChain ในการแปลงฟังก์ชันเป็น Tool ด้วย @tool decorator
# tools.py
import httpx
from langchain_core.tools import tool
import yfinance as yf
import json
@tool
def get_crypto_price(ticker: str) -> str:
"""Get the current price of a cryptocurrency (e.g., 'bitcoin', 'ethereum')."""
try:
url = f"https://api.coingecko.com/api/v3/simple/price?ids={ticker.lower()}&vs_currencies=usd"
response = httpx.get(url, timeout=10)
data = response.json()
if ticker.lower() in data:
price = data[ticker.lower()]["usd"]
return f"The current price of {ticker} is ${price:,} USD."
return f"Could not find price for {ticker}. Please check the coin name."
except Exception as e:
return f"Error fetching price: {str(e)}"
@tool
def get_thai_stock_price(symbol: str) -> str:
"""
Get the current stock price of a Thailand stock (SET) by its symbol.
Example input: 'PTT', 'CPALL', 'BDMS', 'ADVANC'
"""
try:
# จัดการชื่อหุ้นให้อยู่ในฟอร์แมตของ Yahoo Finance (เช่น PTT.BK)
clean_symbol = symbol.strip().upper()
if not clean_symbol.endswith(".BK"):
yf_symbol = f"{clean_symbol}.BK"
else:
yf_symbol = clean_symbol
# ดึงข้อมูลผ่าน Ticker
stock = yf.Ticker(yf_symbol)
# 💡 วิธีที่ชัวร์ที่สุด: ดึงประวัติราคาย้อนหลังสั้นที่สุด (1 วัน ระดับนาที)
# วิธีนี้จะได้ราคาตลาดล่าสุด (Close) และราคาปิดวันก่อนหน้า (Open ของแท่งวัน หรือดึงประวัติเพิ่ม)
hist = stock.history(period="1d")
# ถ้าไม่มีข้อมูลใน Dataframe แปลว่าชื่อหุ้นผิด หรือดึงข้อมูลไม่ได้
if hist.empty:
return f"ไม่พบข้อมูลราคาหุ้นของ {clean_symbol} กรุณาตรวจสอบชื่อย่อหุ้นอีกครั้ง"
# ดึงราคาล่าสุดจากแถวสุดท้ายของคอลัมน์ 'Close'
current_price = float(hist['Close'].iloc[-1])
# ดึงข้อมูลเพิ่มเติมเพื่อหาเปอร์เซ็นต์การเปลี่ยนแปลง
# โหลดเพิ่มอีกเล็กน้อยเพื่อความแม่นยำในการคำนวณราคาปิดวันก่อนหน้า
hist_5d = stock.history(period="5d")
if len(hist_5d) >= 2:
# ราคาปิดของวันทำการก่อนหน้า (แถวก่อนแถวสุดท้าย)
prev_close = float(hist_5d['Close'].iloc[-2])
else:
prev_close = current_price
# คำนวณส่วนต่าง
change = current_price - prev_close
change_percent = (change / prev_close) * 100 if prev_close else 0
# จัดฟอร์แมตข้อความแสดงผล
direction = "📈" if change >= 0 else "📉"
return (
f"ราคาหุ้น {clean_symbol} ล่าสุดในตลาด SET อยู่ที่ {current_price:,.2f} บาท "
f"({direction} {change:+,.2f} / {change_percent:+.2f}%)"
)
except Exception as e:
return f"เกิดข้อผิดพลาดในการดึงข้อมูลหุ้น {symbol}: {str(e)}"
@tool
def generate_comparison_flex_message(title: str, items_json: str) -> str:
"""
Generate a LINE Flex Message JSON string for comparing multiple stocks or cryptos in a table format.
Use this tool ONLY when the user wants to compare, list, or summarize multiple items (stocks/cryptos) together.
Parameters:
- title: The title of the comparison (e.g., 'เปรียบเทียบหุ้นกลุ่มธนาคาร', 'สรุปราคาคริปโตยอดฮิต')
- items_json: A JSON string containing a list of dictionaries with keys: 'name', 'price', and 'change'.
Example: '[{"name": "PTT", "price": "34.25", "change": "+0.50"}, {"name": "CPALL", "price": "65.00", "change": "-0.25"}]'
"""
try:
# แปลงข้อมูล String JSON ที่ LLM ส่งมาให้กลายเป็น Python List
items = json.loads(items_json)
# 1. สร้างแถวของตาราง (Table Rows) จากข้อมูลที่ได้
table_rows = []
for item in items:
name = item.get("name", "-")
price = item.get("price", "-")
change = item.get("change", "-")
# 🚨 [เพิ่มจุดนี้] ดักจับป้องกันกรณีที่ LLM ส่งค่าว่าง "" มาให้เปลี่ยนเป็น "-" แทน
if not change or change.strip() == "":
change = "-"
# กำหนดสีตามการเปลี่ยนแปลง (บวก=เขียว, ลบ=แดง, เท่าเดิม/ไม่มีข้อมูล=เทา)
color = "#27ae60" if "+" in change else ("#c0392b" if "-" in change and change != "-" else "#555555")
row_box = {
"type": "box",
"layout": "horizontal",
"margin": "md",
"contents": [
{"type": "text", "text": name, "size": "sm", "color": "#111111", "flex": 3, "weight": "bold"},
{"type": "text", "text": f"{price}", "size": "sm", "color": "#444444", "flex": 4, "align": "end"},
{"type": "text", "text": change, "size": "sm", "color": color, "flex": 3, "align": "end", "weight": "bold"}
]
}
table_rows.append(row_box)
# 2. ประกอบโครงสร้าง Flex Message (Bubble) ตามดีไซน์ของ LINE
flex_bubble = {
"type": "bubble",
"body": {
"type": "box",
"layout": "vertical",
"contents": [
# หัวข้อ (Header)
{"type": "text", "text": title, "weight": "bold", "size": "md", "color": "#1ca7ec"},
{"type": "separator", "margin": "md"},
# หัวตาราง (Table Header)
{
"type": "box",
"layout": "horizontal",
"margin": "md",
"contents": [
{"type": "text", "text": "ชื่อ", "size": "xs", "color": "#aaaaaa", "flex": 3, "weight": "bold"},
{"type": "text", "text": "ราคาล่าสุด", "size": "xs", "color": "#aaaaaa", "flex": 4, "align": "end", "weight": "bold"},
{"type": "text", "text": "เปลี่ยนแปลง", "size": "xs", "color": "#aaaaaa", "flex": 3, "align": "end", "weight": "bold"}
]
},
{"type": "separator", "margin": "sm"}
] + table_rows # นำข้อมูลแถวที่สร้างไว้มาต่อท้ายหัวตาราง
}
}
# ส่งโครงสร้าง Flex Container กลับไปในรูปแบบ String JSON พิเศษเพื่อระบุว่าเป็น Flex
# เราจะครอบด้วยคำว่า FLEX_JSON: เพื่อให้ไฟล์ app.py ตรวจจับได้ง่าย
return f"FLEX_JSON:{json.dumps(flex_bubble, ensure_ascii=False)}"
except Exception as e:
return f"Error generating Flex Message: {str(e)}"
# รวบรวม Tools ทั้งหมดไว้ใน List เพื่อให้ Agent รู้จัก
tools_list = [get_crypto_price, get_thai_stock_price, generate_comparison_flex_message]
ออกแบบโครงสร้าง Agent ด้วย LangGraph (agent.py) เราจะสร้าง ReAct (Reasoning + Acting) Pattern ซึ่งเป็นรูปแบบดีไซน์ของ Agent ที่คิดก่อน > เลือกใช้ Tool > ดูผลลัพธ์ > แล้วค่อยตอบผู้ใช้ โดยบันทึก Memory แบบ In-Memory (MemorySaver)
# agent.py
from typing import Annotated, TypedDict
from config import Settings
from tools import tools_list
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from langgraph.checkpoint.memory import MemorySaver
from llm_factory import LLMFactory
from langchain_core.messages import trim_messages, SystemMessage
settings = Settings()
# 1. กำหนด State (ข้อมูลที่ไหลเวียนใน Graph)
class AgentState(TypedDict):
# add_messages หมายถึงการ "ต่อท้าย" ข้อความเดิม (Append) ไม่ใช่การลบทับ
messages: Annotated[list, add_messages]
# 2. ตั้งค่า LLM และผูกมัด (Bind) เข้ากับ Tools
llm = ChatOpenAI(
model="typhoon-v2.5-30b-a3b-instruct",
temperature=0,
api_key=settings.typhoon_api_key,
base_url="https://api.opentyphoon.ai/v1" # Target the Typhoon API endpoint
)
llm_with_tools = llm.bind_tools(tools_list)
SYSTEM_PROMPT = SystemMessage(
content=(
"You are a smart financial assistant on LINE. "
"1. If the user asks general questions, math calculations, or advice (e.g., 'มีเงิน 1 ล้านซื้อได้กี่หุ้น'), "
"you MUST answer immediately with a normal text response. DO NOT call the flex message tool. "
"2. Only use 'generate_comparison_flex_message' when explicitly comparing or listing multiple stock/crypto prices. "
"3. CRITICAL: If you receive 'FLEX_JSON:' from a tool, return that exact string and NOTHING else."
)
)
# ตั้งค่าตัวตัดแต่งประวัติข้อความ
trimer = trim_messages(
max_tokens=4, # กำหนดเป็นจำนวนข้อความ (Strategy="last")
strategy="last", # เอาเฉพาะข้อความท้ายๆ ที่เพิ่งคุยกัน
token_counter=len, # นับแบบง่ายๆ: 1 ข้อความ = 1 หน่วย
include_system=True, # เก็บ SystemMessage สำคัญที่หัวแถวไว้เสมอ ห้ามตัดทิ้ง!
allow_partial=False
)
# 3. สร้าง Node: ตัวตัดสินใจ (Agent Node)
def call_model(state: AgentState):
messages = state["messages"]
# รวม System Message แขวนไว้ด้านบนสุด
full_messages = [SYSTEM_PROMPT] + messages
# ✂️ ตัดแต่งกิ่งความทรงจำก่อนส่งให้ LLM
# สมมติคุยมา 100 ประโยค จะเหลือเพียง System Prompt + ข้อความล่าสุด 4 ประโยคเท่านั้น
trimmed_messages = trimer.invoke(full_messages)
response = llm_with_tools.invoke(trimmed_messages)
return {"messages": [response]}
# 4. สร้าง Edge: ตัวกำหนดเงื่อนไข (Conditional Edge)
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
# ถ้า LLM บอกว่าอยากใช้ Tool ให้วิ่งไปที่ Node เครื่องมือ
if last_message.tool_calls:
return "tools"
# ถ้า LLM มั่นใจว่าได้คำตอบแล้ว ให้จบการทำงาน
return END
# 5. ประกอบร่าง Graph
workflow = StateGraph(AgentState)
# เพิ่ม Node ทำงาน
workflow.add_node("agent", call_model)
workflow.add_node("tools", ToolNode(tools_list)) # ToolNode เป็นตัวช่วยสำเร็จรูปของ LangGraph
# เชื่อมเส้นทาง (Edges)
workflow.add_edge(START, "agent")
# ใช้ Conditional Edge เพื่อตัดสินใจหลังจาก Node agent ทำงานเสร็จ
workflow.add_conditional_edges("agent", should_continue)
workflow.add_edge("tools", "agent") # หลังจากใช้ Tool เสร็จ ให้กลับมาให้ Agent ตรวจสอบผลลัพธ์
# 6. Compile พร้อมเปิดใช้งาน In-Memory Checkpointer (Thread Memory)
memory = MemorySaver()
agent_graph = workflow.compile(checkpointer=memory)
เชื่อมต่อ LINE OA ด้วย FastAPI (app.py) ในส่วนนี้เราจะทำ Webhook Server มารับข้อความจาก LINE แล้วดึง user_id ของ LINE มาเป็น thread_id ใน LangGraph เพื่อให้ระบบจำบริบทแชทแยกรายคนได้โดยไม่ต้องพึ่งพาภายนอก Database
# app.py
from fastapi import FastAPI, Request, HTTPException
from linebot.v3 import WebhookHandler
from linebot.v3.exceptions import InvalidSignatureError
from linebot.v3.messaging import (
Configuration, ApiClient, MessagingApi, ReplyMessageRequest, TextMessage,
FlexMessage, FlexContainer
)
from linebot.v3.webhooks import MessageEvent, TextMessageContent
from config import Settings
from agent import agent_graph
import json
import re
settings = Settings()
app = FastAPI()
# ตั้งค่า LINE SDK
line_config = Configuration(access_token=settings.line_channel_access_token)
handler = WebhookHandler(settings.line_channel_secret)
def clean_markdown(text: str) -> str:
"""ฟังก์ชันสำหรับลบสัญลักษณ์ Markdown ทั่วไปออกให้เหลือแต่ Plain Text"""
if not text:
return text
# 1. ลบเครื่องหมายหัวข้อ เช่น ###, ##, # ที่อยู่ต้นบรรทัด
text = re.sub(r'(?m)^#{1,6}\s*', '', text)
# 2. ลบเครื่องหมายตัวหนา/ตัวเอียง เช่น **text** หรือ __text__ หรือ *text*
text = re.sub(r'\*{1,2}(.*?)\*{1,2}', r'\1', text)
text = re.sub(r'_{1,2}(.*?)_{1,2}', r'\1', text)
# 3. ลบเครื่องหมาย Code Block หรือ Inline Code เช่น `text`
text = re.sub(r'`(.*?)`', r'\1', text)
return text.strip()
@app.post("/webhook")
async def webhook(request: Request):
signature = request.headers.get("X-Line-Signature", "")
body = await request.body()
try:
handler.handle(body.decode("utf-8"), signature)
except InvalidSignatureError:
raise HTTPException(status_code=400, detail="Invalid signature")
return "OK"
@handler.add(MessageEvent, message=TextMessageContent)
def handle_message(event: MessageEvent):
user_id = event.source.user_id
user_text = event.message.text
# 1. ดึงสถานะปัจจุบัน (State) ของกราฟออกมาก่อน เพื่อดูว่ามีข้อความเก่ากี่ข้อความ
config = {"configurable": {"thread_id": user_id}}
current_state = agent_graph.get_state(config)
# นับจำนวนข้อความที่มีอยู่ก่อนหน้านี้ (ถ้าเป็นคนใหม่คุยครั้งแรกจะเป็น 0)
existing_msg_count = len(current_state.values.get("messages", [])) if current_state.values else 0
# 2. สั่งให้ LangGraph ประมวลผลคำถามใหม่
inputs = {"messages": [("user", user_text)]}
result = agent_graph.invoke(inputs, config=config)
# 3. สกัดเอาเฉพาะ "ข้อความใหม่" ที่เกิดขึ้นในรอบนี้เท่านั้น (ตัดประวัติเก่าทิ้งไปในการพิจารณา)
all_messages = result["messages"]
new_messages = all_messages[existing_msg_count:] # ดึงเฉพาะข้อความลำดับหลังจากข้อความเก่า
# 4. ค้นหาหา Flex JSON เฉพาะในกลุ่มข้อความใหม่เท่านั้น
flex_json_found = None
for msg in reversed(new_messages):
if isinstance(msg.content, str) and "FLEX_JSON:" in msg.content:
raw_content = msg.content
start_idx = raw_content.find("FLEX_JSON:")
flex_json_found = raw_content[start_idx:].replace("FLEX_JSON:", "", 1).strip()
break
# 5. ตัดสินใจส่งข้อความกลับไปยัง LINE
with ApiClient(line_config) as api_client:
line_bot_api = MessagingApi(api_client)
if flex_json_found:
try:
flex_content = json.loads(flex_json_found)
message_to_send = FlexMessage(
alt_text="สรุปข้อมูลเปรียบเทียบ",
contents=FlexContainer.from_dict(flex_content)
)
except Exception:
# Fallback หาก JSON โครงสร้างพัง
message_to_send = TextMessage(text=clean_markdown(all_messages[-1].content))
else:
# 🚨 หากในรอบนี้ไม่มีการเรียก Tool ทำ Flex เลย ให้เอาข้อความสุดท้าย (ซึ่งตอบเรื่องเงิน 1 ล้าน) ส่งไป
raw_reply = all_messages[-1].content
clean_reply = clean_markdown(raw_reply)
message_to_send = TextMessage(text=clean_reply)
line_bot_api.reply_message_with_http_info(
ReplyMessageRequest(reply_token=event.reply_token, messages=[message_to_send])
)
วิธีการทดสอบและรันโปรเจกต์ จำเป็นจะต้องติดตั้ง Ngrok (ตามคลิปสอนใช้งาน LINE ด้านบน หากดูรายละเอียดเรื่อย ๆ จะมีสอน) การทดสอบทำได้ดังนี้
- รันเซิฟเวอร์บนเครื่องตัวเองที่ Port 8000
- เปิด Ngrok ที่ Port 8000
- นำลิงก์ HTTPS ของ Ngrok ตามด้วยพิมพ์ /webhook ต่อท้ายลิงก์นั้นไปวางใน LINE Messaging API Webhook เพื่อเชื่อมต่อ
จากนั้นจะสามารถทดสอบใช้งานแชทคุยกับ AI ได้
uv run uvicorn app:app --reload --port 8000
ngrok http 8000
อธิบายเพิ่มเติมในขั้นตอนสร้าง Agent
วิธีใช้งาน LangGraph ที่เราทำใน agent.py นั้นมีรายละเอียดดังนี้
- การกำหนดหน่วยความจำส่วนกลาง (AgentState)
- หน้าที่: เป็น “สมุดจดบันทึกประจำรอบการทำงาน” (State) ที่เก็บข้อมูลที่ทุกๆ Node ต้องใช้อ่านและเขียนร่วมกัน
- จุดสำคัญ: การใช้ Annotated[list, add_messages] หมายความว่า ทุกครั้งที่มีข้อมูลส่งเข้ามาใน State นี้ ระบบจะทำการ “ต่อท้าย (Append)” เข้าไปในลิสต์ข้อความเดิม ไม่ใช่การลบทับ ทำให้เราเก็บประวัติการคุย (Chat History) ได้โดยอัตโนมัติ
2. การตั้งค่าโมเดลและเครื่องมือ (LLM & Bind Tools)
หน้าที่: โหลดโมเดลภาษาภาษาไทย (ในโค้ดเลือกใช้ typhoon-v2.5-30b) และทำระบบ bind_tools
จุดสำคัญ: การจับโมเดลมา bind_tools จะเป็นการบอกให้ LLM รับรู้ว่า “นอกจากนั่งเดาคำตอบแล้ว เธอมีสิทธิ์เลือกหยิบฟังก์ชันเหล่านี้ใน tools_list ไปรันเพื่อหาคำตอบที่แท้จริงได้นะ”
- เพิ่มเติม การควบคุมพฤติกรรม (System Prompt & Message Trimmer):
- SYSTEM_PROMPT: เป็นกฎเหล็กที่ฝังในหัวข้อ LLM คอยสั่งห้ามใช้สัญลักษณ์ Markdown และแยกแยะว่าคำถามไหนควรตอบธรรมดา คำถามไหนควรใช้ Tool สรุปราคาหุ้น/คริปโต
- trimer (Message Trimmer): ทำหน้าที่ตัดประวัติแชทเก่าๆ ที่ยาวเกินไปทิ้ง โดยจะเหลือแค่ System Prompt + ข้อความล่าสุด 4 ข้อความเท่านั้น ช่วยแก้ปัญหาบอทมโนฝังใจกับข้อมูลเก่า (Memory Hallucination) และช่วยประหยัด Token ได้อย่างดีเยี่ยม
3. สถานีตัดสินใจและประมวลผล (call_model Node)
หน้าที่: สถานีนี้คือ “สมอง” ของ Agent เมื่อได้รับข้อมูลข้อความล่าสุดมา มันจะเอาเข้าเครื่องตัดประวัติแชทด้วย trimer แล้วส่งต่อให้ LLM คิด
ผลลัพธ์: ขากลับโมเดลจะส่งคำตอบกลับมา (อาจเป็นข้อความตอบกลับมนุษย์ธรรมดา หรือเป็นคำสั่งขอเรียกใช้เครื่องมือที่มีโครงสร้าง tool_calls) และบันทึกคำตอบนั้นกลับเข้าไปใน AgentState
4. ป้ายบอกทางตามเงื่อนไข (should_continue Conditional Edge)
หน้าที่: ทำหน้าที่เป็น “ตำรวจจราจร” คอยสับรางรถไฟหลังจากออกจากสถานีสมอง (call_model) โดยจะหันไปดูข้อความล่าสุดในสมุดจด
เงื่อนไขการสับราง:
ถ้าเจอว่า LLM เขียนแปะไว้ว่าอยากใช้เครื่องมือ (last_message.tool_calls) -> จะสับรางส่งรถไฟไปที่สถานี tools
ถ้าเจอข้อความตอบกลับทั่วไป ไม่มีคำสั่งใช้เครื่องมือ -> จะสับรางส่งรถไฟไปที่จุด END เพื่อส่งคำตอบกลับเข้า LINE OA ทันที
5. ประกอบร่างแอปพลิเคชัน (Graph Workflow)
หน้าที่: นำเอาสถานีทำงาน (Nodes) และเส้นทางการเดินรถ (Edges) มาร้อยเรียงเชื่อมเข้าด้วยกัน
ทิศทางการวิ่งของข้อมูล:
เริ่มต้นที่จุด START ยิงตรงไปสถานี agent
ออกจาก agent วิ่งผ่านประตูกลั่นกรองเงื่อนไข should_continue
หากเงื่อนไขบอกให้ไปต่อ ก็จะวิ่งเข้าสถานีลงมือทำ tools
หลังจากรัน Tool เสร็จ เส้นทางจะบังคับลาก workflow.add_edge(“tools”, “agent”) เพื่อส่งข้อมูลผลลัพธ์ที่ได้จากการรัน Tool กลับไปให้สถานีสมองตรวจทานอีกรอบหนึ่งเสมอ วนลูปจนกว่างานจะจบ
6. คอมไพล์เปิดระบบพร้อมหน่วยความจำระยะยาว (Compile & MemorySaver)
หน้าที่: หลอมรวมโครงสร้างกราฟทั้งหมดให้กลายเป็นอ็อบเจกต์ตัวเดียวชื่อ agent_graph ที่พร้อมใช้งาน
จุดสำคัญ: การใส่ checkpointer=memory (ผ่าน MemorySaver) คือการเปิดระบบเปิดกล่องเซฟความทรงจำแบบ In-Memory ทำให้บอตตัวนี้จำบริบทแยกรายห้องแชท (Thread ID) ได้แบบเรียลไทม์ โดยไม่ต้องเชื่อมต่อฐานข้อมูลภายนอกให้ซับซ้อน
Conclusion
“LangGraph คือเครื่องมือปั้น Agentic AI ที่ช่วยเปลี่ยนจากบอทนั่งเดาคำตอบแบบเส้นตรง ให้กลายเป็นระบบ AI ที่คิดเป็นระบบ ทำงานเป็นขั้นตอน วนลูปแก้ไขตัวเองได้ และจำบริบทการทำงานได้อย่างแม่นยำ”
มีการทำงานเป็นแบบ Graph ที่มีองค์ประกอบสำคัญคือ Nodes และ Edges ที่เป็นฟังก์ชันและเงื่อนไขในการทำงาน มาพร้อมกับการทำงานแบบวนลูปเป็น Cycle แบบอัตโนมัติช่วยให้ Agent ตรวจทานงานและคิดใหม่ทำใหม่จนกว่าจะได้ผลลัพธ์ที่ดีได้